In this page, we provide some statistics about the dataset generation process and the final dataset used in our experiments.
Our generation process combines different existing datasets of acoustic scenes and isolated sound events to create mixture acoustic scenes with clean separated sources.
Here are the datasets we used in the paper:
- Background sounds: Dcase2018 Task 1, CochlScene, Arte, Cas2023, LitisRouen
- Isolated events: ESC-50, ReaLISED, VocalSound, FreesoundOneShotPercussive, Nonspeech7k
For both types of sounds, we also generated synthetic sounds to increase the diversity of the training data (see the GitHub repository for more details).
Existing datasets chosen for the impulsive-stationary sound separation task may require some pre-processing to ensure that the sounds are suitable for the task. The background sounds should be impulsive event-free and the isolated impulsive sounds should be genuinely impulsive.
After this, we unify all the datasets labels to have a common taxonomy using the Salt framework. This is useful to generate a balanced and diverse dataset.
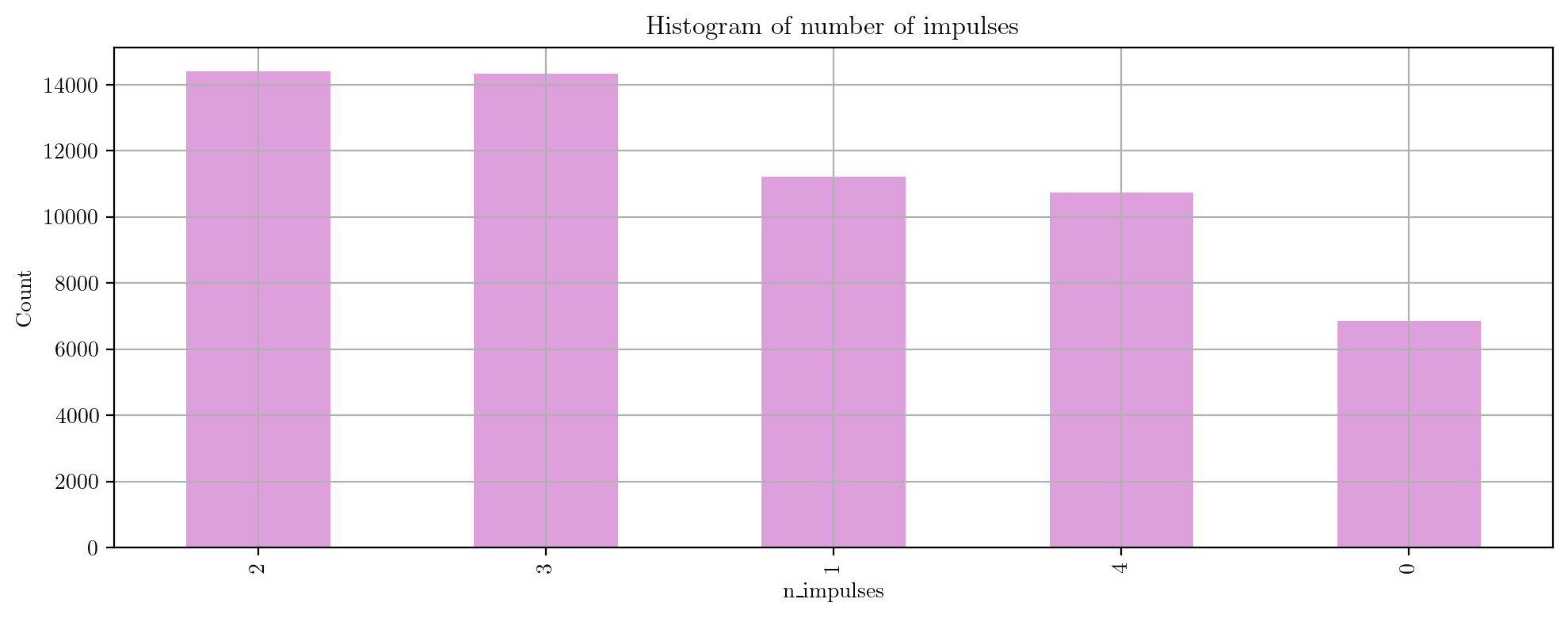
Finally, we generate the mixture scenes by randomly combining background sounds and 0 to 5 isolated impulsive events.
Here are some statistics about the datasets used in the paper that underline the value of using a common taxonomy through SALT.
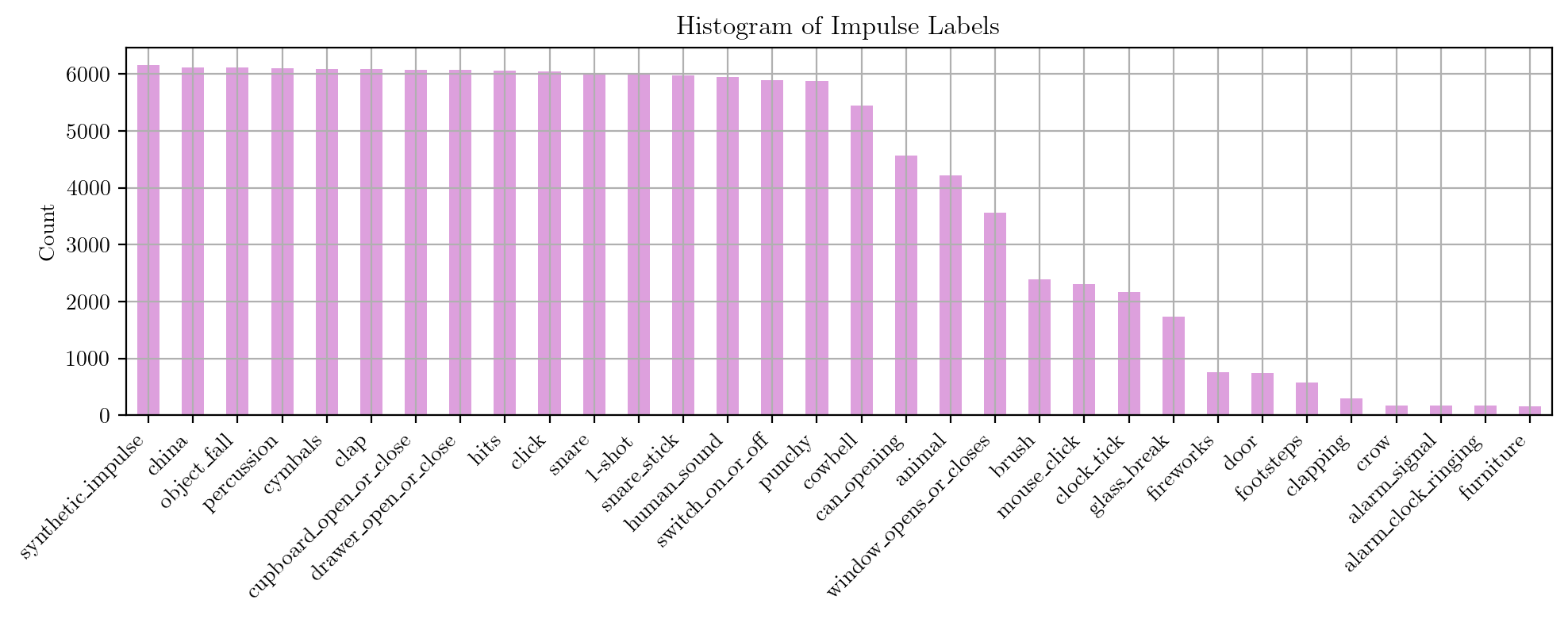
Impulsive sound events
After “cleaning” the isolated impulsive sound datasets, here are some statistics about the isolated events datasets.
First we represent the label distribution of the isolated impulsive sound events using the standard and unified labels from our taxonomy. Secondly we represent the duration distribution of the isolated impulsive sound events, and finally the dataset distribution in terms of number of files.
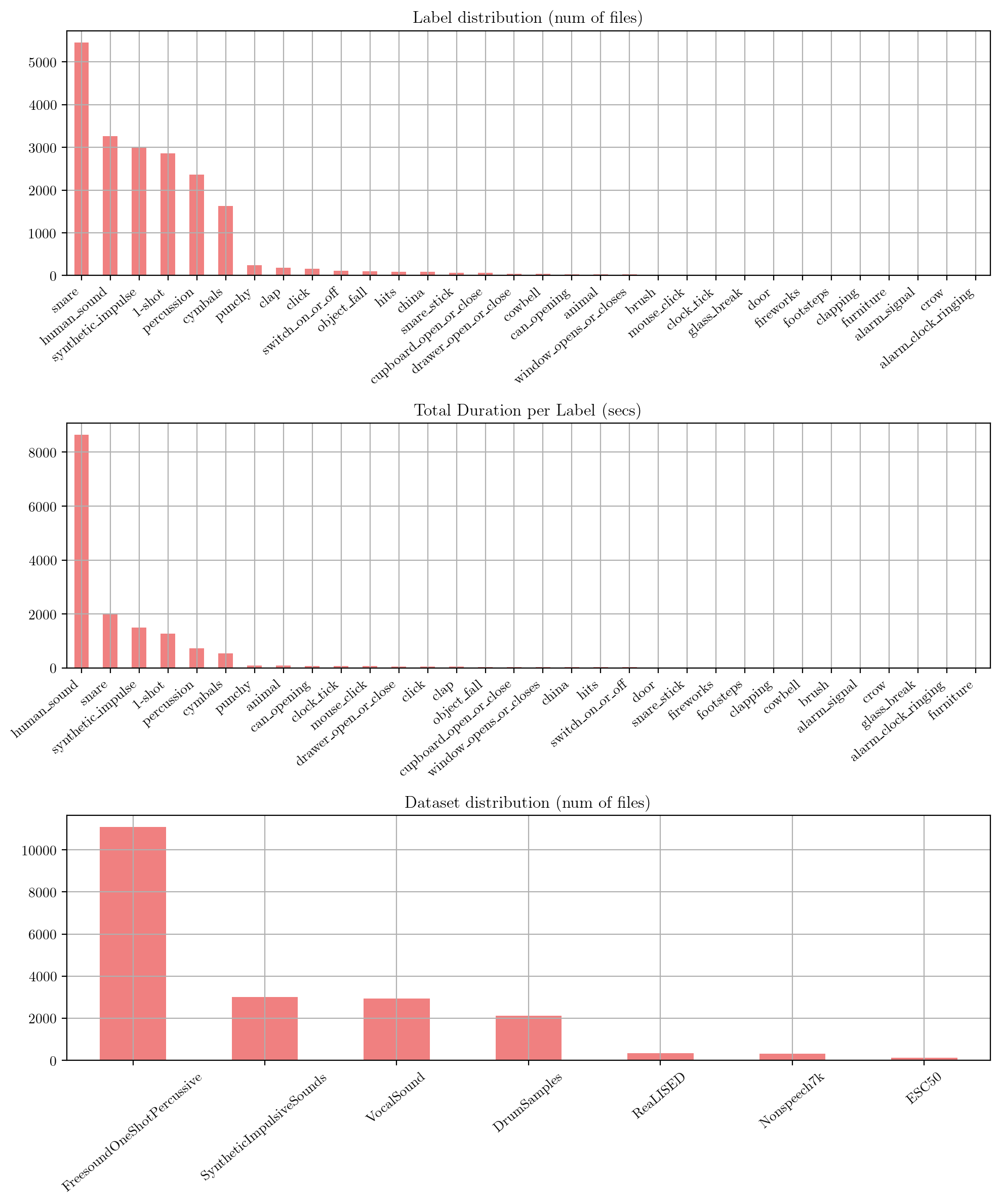
The label distribution reveals significant imbalance, with percussive and human sounds being over-represented, while other categories such as footsteps, alarms, and door sounds are under-represented. This disparity is evident both in the number of files and their total duration. Such imbalance can be attributed to the varying sizes of the source datasets, particularly after the removal of non-impulsive events, which substantially reduces the size of certain datasets, as well as the underrepresentation of certain labels within the datasets themselves.
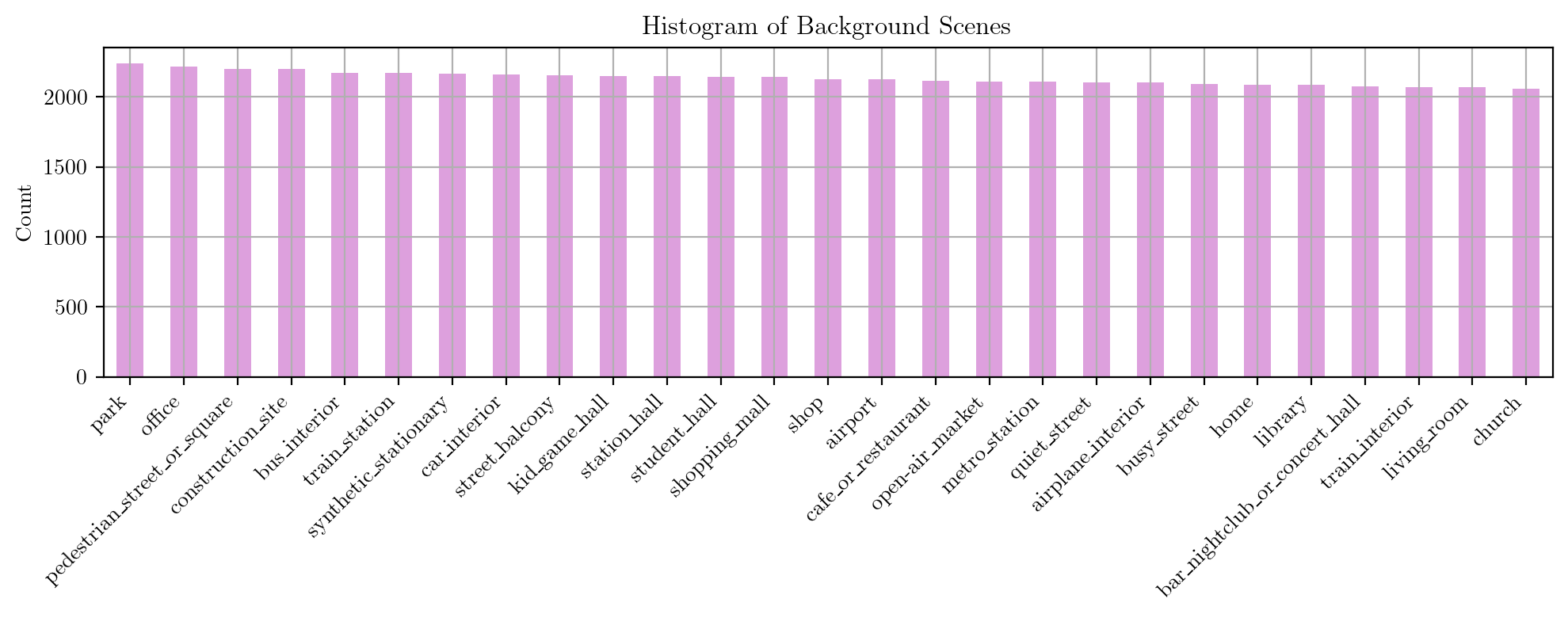
Background sounds
Similarly, we provide some statistics about the background sound datasets after removing impulsive events and keeping only audio files with a duration longer than 5s.
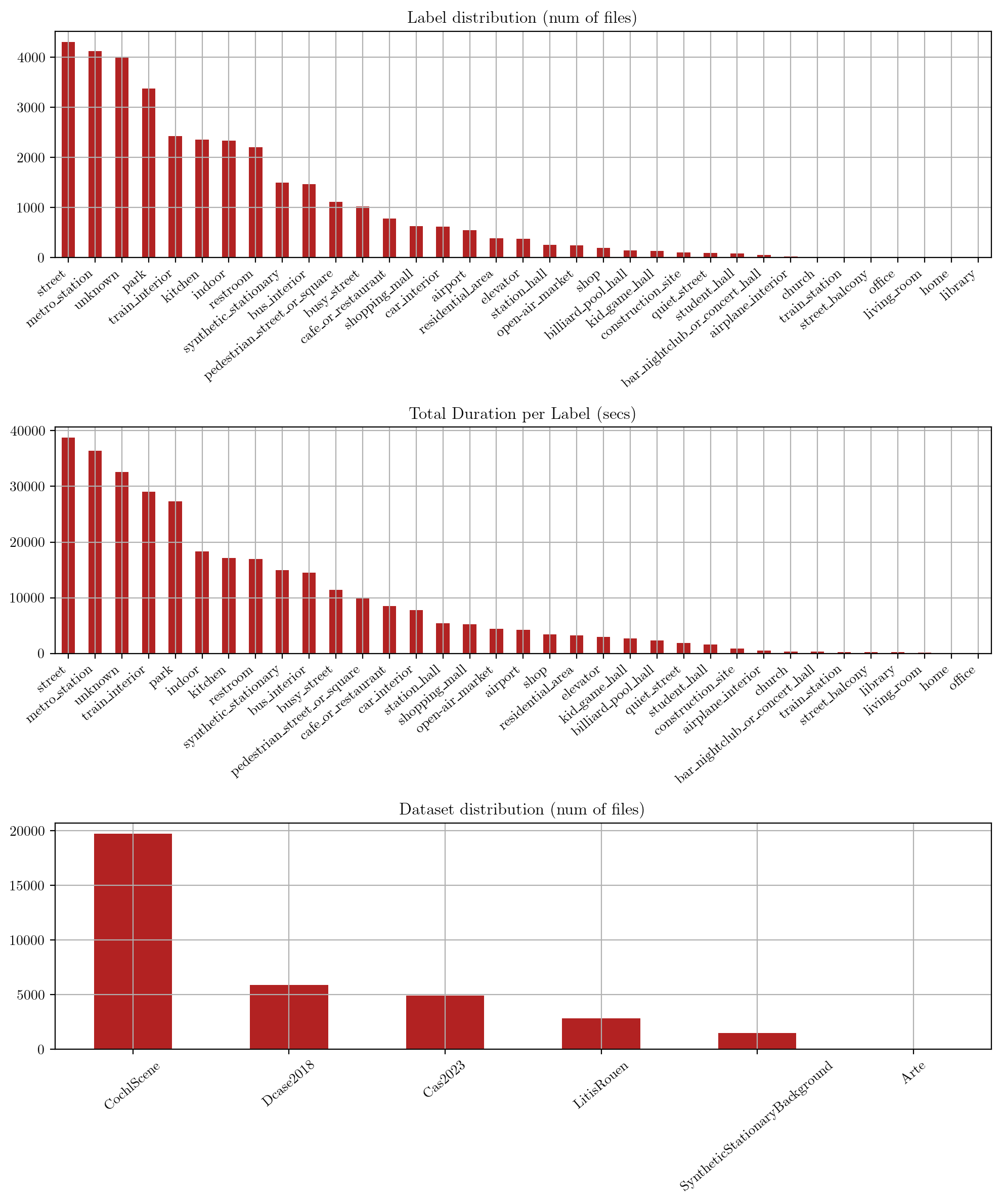
The label distribution of the background sounds is slightly more balanced than that of the impulsive sounds, but there are still some categories that are under-represented, such as “train_station” or “airplane_interior”.
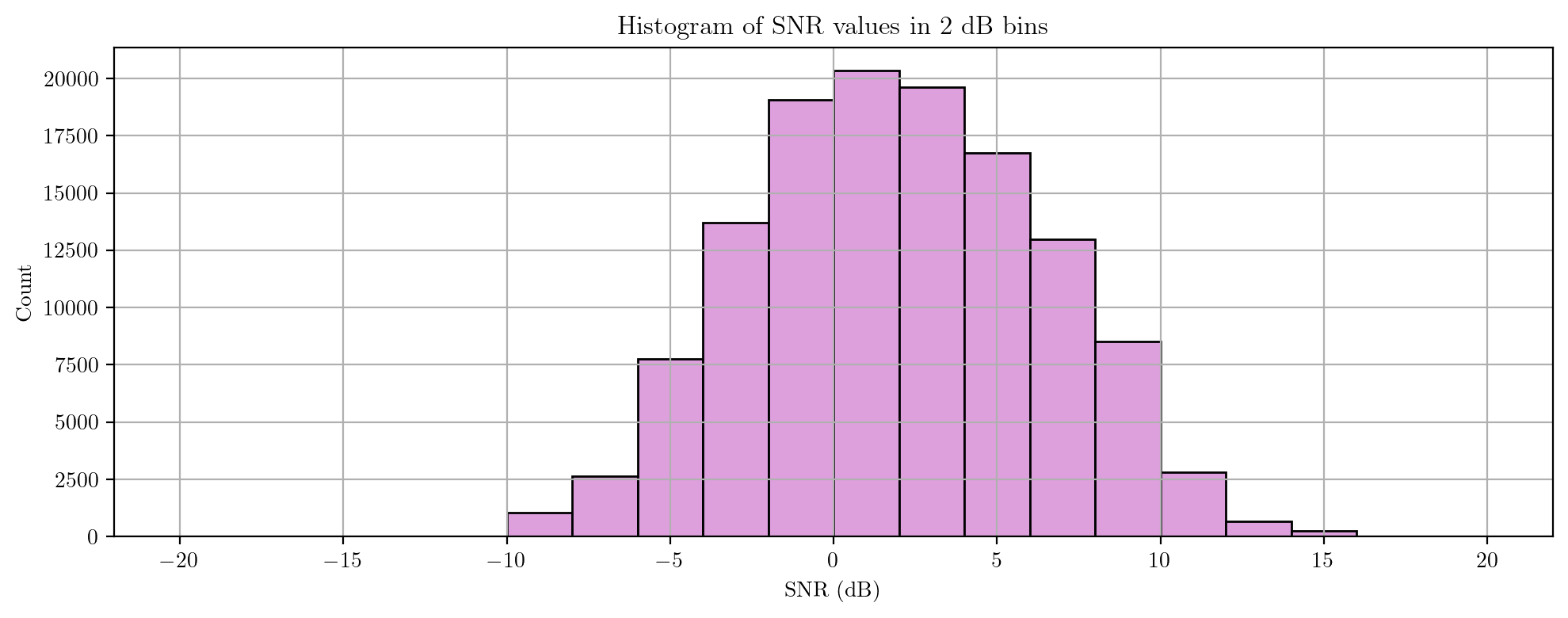
Generated dataset
Finally, we provide some statistics about the generated dataset used in our experiments.